Are you tired of the tedious process of editing, scraping, or extracting data from PDF files?
The Portable Document Format (PDF) may be the go-to file format for sharing and exchanging business data. Still, editing, scraping, or extracting data from PDF files can be a hassle. Imagine the time and effort saved by efficiently extracting text, tables and integrating it with your ERP, E-commerce store, Accounting, or other back-end business system!
This blog will discuss the challenges in PDF data extraction and the five most popular ways businesses extract data from PDFs. From the traditional copy-and-paste method to outsourcing manual data entry, PDF converters, PDF table extraction tools, and automated PDF data extraction.
We will also discuss the latest technological advancements to extract data from PDF documents efficiently. So, if you want to streamline your data extraction or document processing process, this blog is for you!
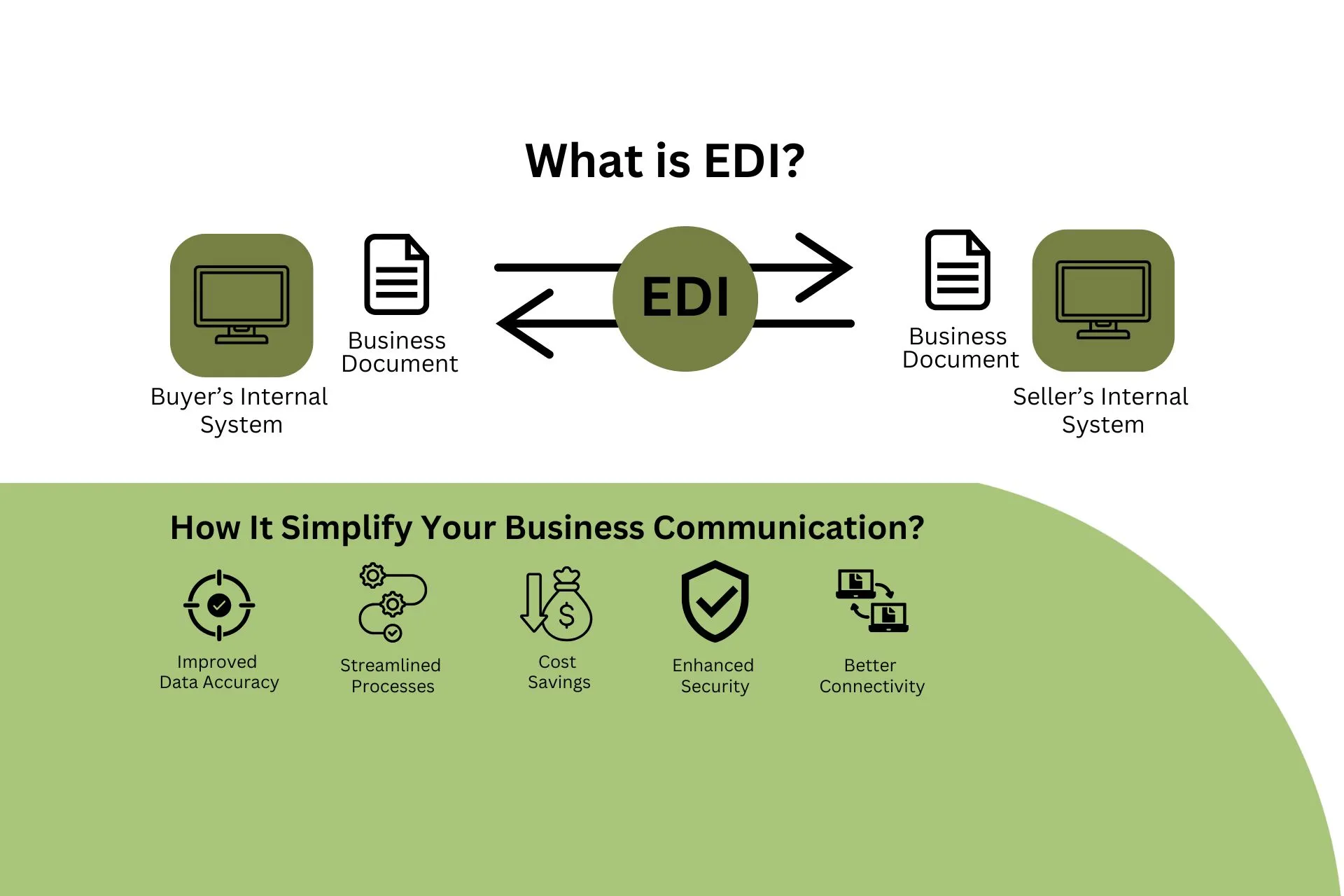
Challenges in PDF data extraction
You’re not alone if you’re having difficulty extracting data from PDFs. Unlike other document formats such as DOC, XLS, or CSV, traditional methods of extracting data from PDFs, such as editing or copy-pasting, often result in losing original formatting and order, making it complicated.
These challenges can negatively affect your business, especially when dealing with large amounts of PDF data extraction.
However, thanks to technological advancements, solutions like HubBroker’s PDF2XML can extract data from PDFs efficiently.
But before we dive into the high efficiency of PDF2XML solution, let’s examine the five most commonly used methods for extracting data from PDFs used by businesses.
Copy and paste
While practical for a limited number of basic PDFs, the copy-and-paste method can lead to inconsistent and unreliable data extraction. It involves manually opening each PDF, selecting specific data or text, copying it, and pasting it onto a DOC, XLS, or CSV file.
However, this method requires significant time and effort to reorganize the extracted information into a proper format.
Outsourcing manual data entry
Manually extracting data from a large number of PDF documents in-house can become a costly and time-consuming task. Outsourcing manual data entry is a common alternative, as it can be less expensive and faster. There are various online services that connect businesses with data entry professionals from different regions around the world.
However, when outsourcing manual data extraction, it is vital to consider the potential risks of data security and quality control.
As such, many companies are turning to more advanced and secure methods of data extraction, such as automation and automated data extraction solutions. These methods can reduce not only costs but also improve data accuracy and security.
PDF converters
While PDF converters can be a useful solution for those looking to manage data extraction in-house and maintain data quality and security, they have significant limitations when it comes to handling large volumes of documents.
These tools are typically not equipped to handle bulk data extraction and require the user to process each document one at a time manually. This can be time-consuming and inefficient, particularly for businesses dealing with a high volume of PDFs on a regular basis.
Additionally, these tools may not be able to extract data in a format that is suitable for a specific use case and might require additional manual effort to process the extracted data.
Therefore, it is crucial to consider the scale of the data extraction needs before deciding to use PDF converters as a solution.
PDF table extraction tools
PDF documents often contain a variety of information, including tables, text, images, and figures. However, the data that is most important is often found within tables.
Unfortunately, traditional PDF converters don’t have the capability to extract specific sections of a PDF, such as specific cells, rows, columns, or even tables. This can make it difficult to extract the exact data that you need.
PDF table extraction tools, such as Tabula and Excalibur, offer a solution to this problem. These tools allow you to select specific sections of a PDF by drawing a box around a table and then extracting the data into an Excel file (XLS or XLSX) or CSV.
While PDF-to-table tools can be efficient, they may require development effort or in-house expertise to customize for your specific needs. Also, these tools only work with native PDF files and cannot be used with scanned documents, which are more commonly used by businesses.
Automated PDF data extraction
Automated document data extraction solutions like HubBroker’s PDF2XML offer a comprehensive and effective solution for extracting data from PDFs or extracting text from images. They are highly reliable, efficient, and incredibly fast, making them an ideal choice for businesses of all sizes. Additionally, these solutions are competitively priced, secure, and scalable, making them a great investment.
One of the key benefits of these automated PDF data extractors is that they can handle both scanned documents as well as native PDF files, providing a versatile solution to data extraction.
These automated PDF data extraction tools employ a combination of advanced techniques such as AI, ML/DL, OCR, RPA, pattern recognition, text recognition, and more to extract data accurately and at scale. For example, PDF2XML uses machine learning to provide pre-trained extractors that can handle specific types of documents. This means that businesses can easily and quickly extract data from a wide range of documents without the need for extensive development efforts.
Another great feature of these automated PDF data extraction tools is the ability to build custom AI to extract data from different types of documents.
Overall, automated document data extraction solutions like PDF2XML provide a highly effective and efficient solution for extracting data from PDFs and other documents, making them an excellent investment for businesses of all sizes.
Conclusion
PDFs are a widely used format for storing and sharing important business documents, but extracting data from them can be a time-consuming and error-prone task. Many businesses rely on manual data entry or low-cost outsourcing, but these methods can lead to quality control issues and data security risks. Automated data extraction solutions, like HubBroker’s PDF2XML, is the ultimate solution for extracting data from PDFs, emails and other formats.
PDF2XML is a comprehensive solution that combines AI, machine learning, OCR, RPA, and other technologies to extract data accurately and at scale. It can handle both scanned and native PDF files and can even be trained to extract data from specific types of documents. This flexibility allows businesses to extract data quickly and efficiently without sacrificing accuracy or security.
HubBroker’s PDF2XML has helped companies increase their data extraction speed by 90% while maintaining 99% accuracy. It has also helped reduce the cost of data extraction by 74% and ensured data security by providing a secure data transfer.
Don’t waste time and money on manual data entry or low-cost outsourcing. Invest in a dependable and efficient solution like HubBroker’s PDF2XML. Contact us today to see how it can revolutionize your data extraction process.